
The IoT is developing by leaps and bounds, but managing all those devices and data can be difficult.
You must think about managing the data of the many devices they produce. That’s much pressure for any business.
Fog computing can help take some of that burden off your shoulders. It distributes the processing load for IoT devices over a network of computers, making it easier for businesses to manage their data and devices.
In this blog post, we explore the definition of fog computing, followed by its example, Fog computing architecture, and working. We also discuss the challenges, likes, and dislikes associated with it.
Fog Computing Definition
Fog computing is the extension of cloud computing to include wireless devices used by consumers and businesses close to where the data is created or used.
The fog extends the cloud to the network’s edge, providing a new level of intelligence and service for applications and services supporting the Internet of Things (IoT).
Fog nodes are devices such as smartphones, tablets, sensors, wearables, vehicles, appliances, or any other connected endpoint.
Fog nodes can be used to provide proximity-based services such as enhanced mobile broadband (eMBB), Vehicle-to-everything (V2X) communications, or home and building automation.
History of Fog Computing
Cisco partnered with Microsoft, Dell, Intel, Arm, and Princeton University to create the OpenFog Consortium 2015. Other companies like General Electric (GE), Foxconn, and Hitachi also worked on it. The goal was to make fog computing more popular and consistent. The consortium joined the Industrial Internet Consortium in 2019.
Fog Computing Examples
An example is using edge devices, such as sensors or cameras, to collect data and send it to a nearby gateway or server for processing. This way, critical data can be processed closer to where it was generated, reducing latency issues.
One more example is the smart city. In a smart city, many of the devices are connected to the internet and can communicate with each other.
That allows for devices to share data and collaborate to make decisions. For example, traffic lights can be controlled based on real-time traffic data.
Architecture and Working of Fog Computing
Fog computing architecture is a decentralized networking model that takes compute and storage resources closer to the data source or user.
The fog layer sits between the end devices and the cloud, providing intermediate storage and processing.
That allows data to be processed and acted on closer to where it is generated, reducing latency and improving performance.
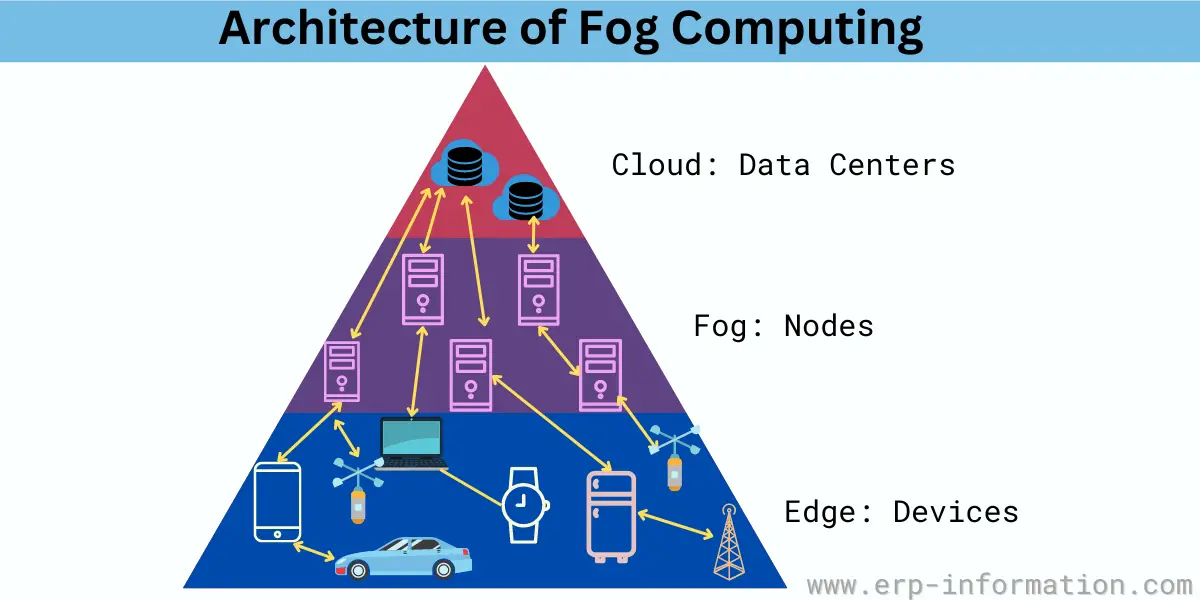
- Step One: Data is collected from various devices and sensors connected to the internet.
- Step Two: That data is then sent to a fog node, which can be anything from a smartphone to a smart thermostat.
- Step Three: The fog node processes the data and sends it back to the devices or sensors.
- Step Four: The fog node sends the data to a central cloud server.
- Step Five: The data is then processed by the cloud server and stored in a database.
Here, instead of all data and processing traveling to a centralized cloud platform, part of the processing and storage happens at the network’s edge in local devices or nodes.
Challenges of Fog Computing

- Increased complexity: It can not be easy to manage all the devices connected to the internet. Fog nodes can help, but they can also add more complexity.
- Needs more power: It requires a lot of power, which can be a problem for battery-powered devices.
- Hard to track devices: It can be hard to keep track of all the devices connected to the internet.
- Difficult to maintain consistency: Fog nodes must maintain high consistency across data.
- Hard to scale: Fog nodes need to be able to scale quickly and handle variable loads.
Likes
- Increased efficiency and decreased latency: This distributed or “foggy” architecture helps reduce network latency and bandwidth congestion, making it well-suited for real-time applications such as autonomous vehicles, augmented reality/virtual reality (AR/VR), and smart cities.
- Increased reliability: It can help improve system reliability by distributing tasks and data across multiple nodes, avoiding single points of failure.
- Enhanced security: It can help to improve safety by providing an extra layer of protection between devices and the cloud.
- Automate tasks: By leveraging artificial intelligence (AI) and machine learning (ML), fog platforms can automate tasks.
- Reduced cost: We can help to reduce costs by allowing devices to share resources such as processing power, storage, and bandwidth and by reducing the data storage that needs to be sent to the cloud.
- Greater flexibility: It provides greater flexibility than traditional cloud-based models, enabling organizations to deploy apps and services where they are most needed.
Dislikes
Fog computing can be
- Unreliable because of its distributed nature.
- Slow because of the need to communicate with multiple nodes.
- Insecure because of the lack of central control.
- Complex to set up and manage.
- Not suitable for all applications.
Where is Fog Computing Needed?
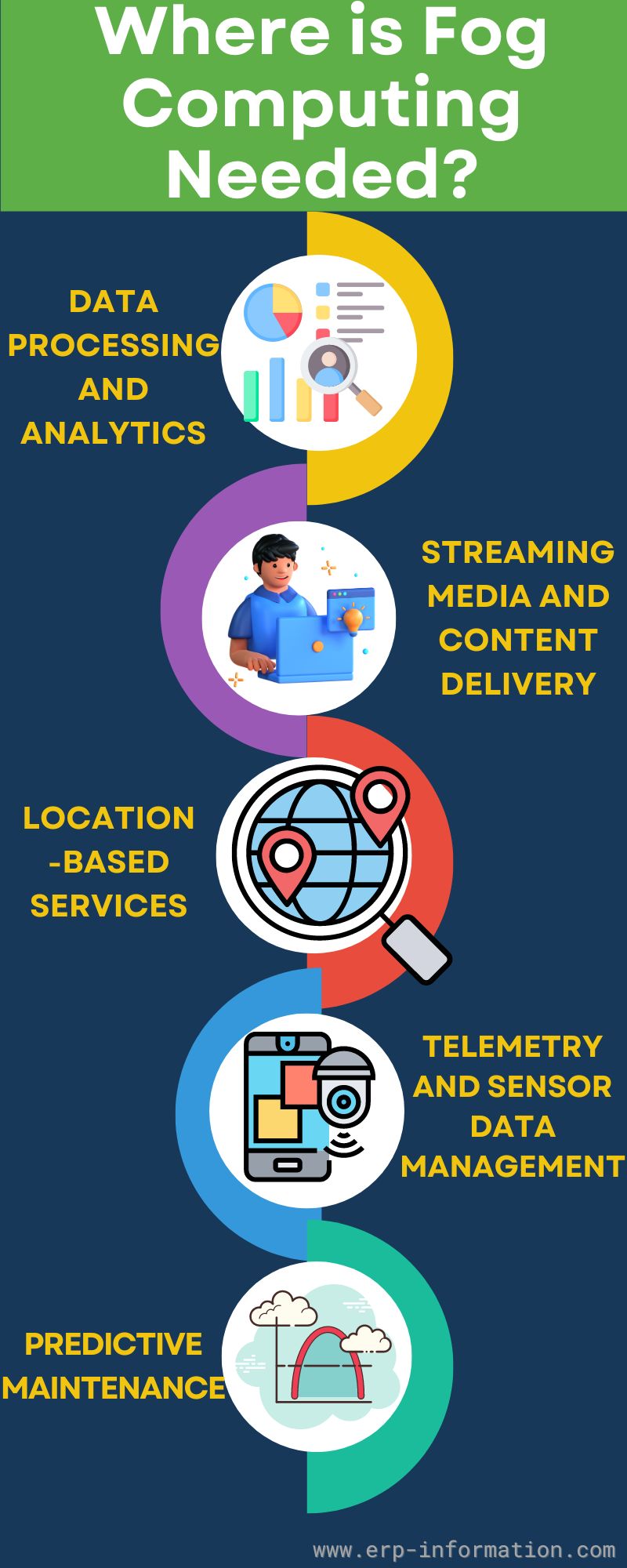
Fog computing is increasingly used in various industries, including automotive, healthcare, retail, and manufacturing. Some typical applications include,
- Data processing and analytics
- Streaming media and content delivery
- Location-based services
- Telemetry and sensor data management
- Predictive maintenance
Relation of Fog Computing with the Internet of Things and 5G
Cloud computing is not always the best choice for things like the Internet of Things and the Industrial Internet of Things. Fog computing is better, as it reduces the amount of data that needs to be sent back and forth between sensors and the cloud. This makes IoT and IIoT work better because it takes less time to process the data.
Fog computing is a way to quickly get data from Internet of Things (IoT) devices. The nodes receive the data and process it right away. Then they send back a summary of the data to the cloud, which can be used to learn more about what happened.
This architecture needs more than just computing power. If you want the data to be processed very fast, like in milliseconds, It needs to connect with IoT devices and nodes quickly.
The connection options depend on what you are using it for. A sensor in a factory can use a wired connection, but something that moves around, like a car or something far away, will need another option. 5G is especially good because it gives us quick connections to analyze the data almost instantly.
Scenarios to use fog computing
- Selective data transfer: Fog computing transfers selective data to the cloud. Moving long-term and not frequently used data by the host.
- Low latency: It is used when data should be analyzed within a fraction of a second.
- Providing services to large areas: Fog computing is used in different geographical large areas.
- Devices subjected to more calculations: Devices that need lots of calculations and processing should use fog computing.
FAQs
Which company first coined fog computing?
Cisco first coined the term for dispersed cloud infrastructure In 2012.
What is the difference between fog computing and edge computing?
Fog computing typically refers to a network that extends beyond the edge of the data center, while edge computing takes place within or very close to the data center.
Conclusion
Fog computing is a way to connect devices and people using the internet. Fog nodes help connect different parts of the internet.
It can be used for various things, but sometimes it can be hard to use because it’s new or some problems must be fixed.
Fog computing has many benefits, but some challenges need to be addressed. However, it can potentially revolutionize how we connect and interact with devices and systems.
Reference