
Apache Kafka is a system that stores and processes events. It is open-source, written in Java and Scala, and developed by the Apache Software Foundation.
Kafka aims to provide a platform that can handle real-time data efficiently with high throughput and low latency.
For data import/export, Kafka can connect to external systems via Kafka Connect. For stream processing applications, Kafka provides the Kafka Stream libraries.
The TCP-based protocol that Kafka uses is optimized for efficiency and uses message sets to group messages together, reducing network overhead.
This blog post will give you an overview of Apache Kafka, its use, how to implement it, who can use it, and its pros and cons.
Latest version: 3.7.0
Released date: February 27, 2024
More about Apache Kafka
Kafka was developed at LinkedIn and became open source in early 2011. Apache Kafka uses a commit log, allowing users to subscribe and publish data to different systems or real-time applications.
Kafka supports two types of topics: Regular and compacted
Regular topics
It can be set with a retention time or space bound. Kafka can delete old data if records are older than the retention time specified or if the space-bound is exceeded for a partition. The default topic setting is a retention time of 7 days, but it’s also possible to store data forever.
Compacted topics
Meaning that records don’t expire based on time or space bounds. Instead, Kafka treats later messages as updates to older messages with the same key and guarantees never to delete the latest message per key.
Users can delete messages by writing a tombstone message with a null value for a specific key.
Apache Kafka is an event-streaming technology that enables organizations to collect and process vast amounts of data.
It helps companies to store large volumes of data, send and receive messages in real-time and enable stream processing applications.
What is Event Streaming?
Event streaming is when data is captured in real-time from event sources. This means that the data is collected as it happens, and it is stored so it can be used later. Event streaming also allows you to look back at data and see what has happened in the past.
Uses of Event Streaming
- Real-time financial transaction and payment processing
- Event streaming helps us understand what is happening with equipment by continuously capturing and analyzing sensor data.
- Monitors the logistics and is useful for the automotive industry
- Useful to collect and immediately interact with customer orders
- To watch patients in the hospital and figure out when their condition might change so we can give them emergency care if they need it.
- To gather all the data from each section of the company and put it in one place where everyone can see and use it.
- It serves as a foundation for data services.
This gives businesses unprecedented speed and flexibility in leveraging their data for insight.
In addition, Apache Kafka is reliable, scalable, fault-tolerant, and secure, offering companies the potential to improve their operational efficiency and performance dramatically.
Use Case of Kafka
Kafka Messaging
Kafka is a messaging system that can quickly handle large amounts of messages. It also has built-in features to keep messages safe in case of problems like power outages or network issues.
Website activity tracking
Kafka was designed to recreate a user activity tracking pipeline using a set of real-time publish-subscribe feeds.
The site activity, like page views, searches, or other actions, is published to central topics, with one topic for each activity type. These feeds are available for subscription by anyone who wants them.
Metrics
Kafka is often used to collect data from different sources and bring it together in one place. This can be useful for monitoring, as it lets you get a centralized view of what is happening.
Log aggregation
Processing pipelines create graphs of real-time data flows based on individual topics. A lightweight but powerful stream processing library called Kafka Streams is available in Apache Kafka to perform such data processing as described above. Alternative open-source stream processing tools include Apache Storm and Apache Samza.
Event sourcing
Event sourcing is a revolutionary way of designing applications; instead of just keeping track of app changes, Kafka logs them as an ever-growing sequence so that past events can be used to build up recent states.
This modern approach allows efficient data storage and retrieval—making it possible for apps to scale while retaining all their information.
Commit log
Kafka is a powerful distributed system that acts as an external commit log, keeping data replicated and in sync between nodes.
In the event of failure, Kafka’s log compaction feature can seamlessly restore lost information – giving it functions similar to Apache BookKeeper.
Some Screenshots of Apache Kafka
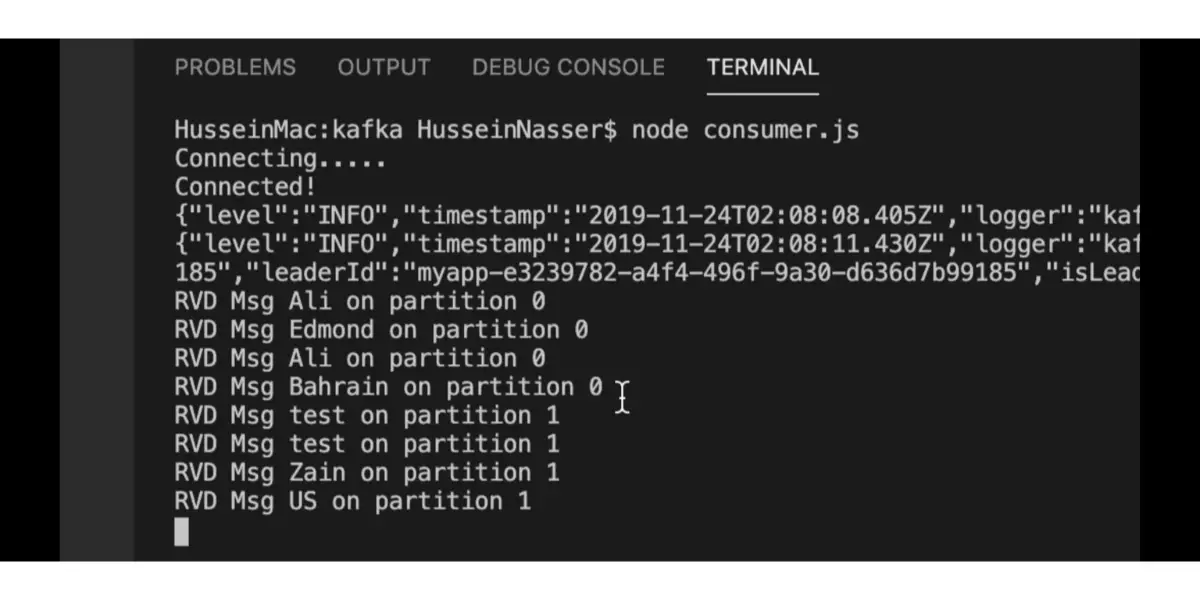
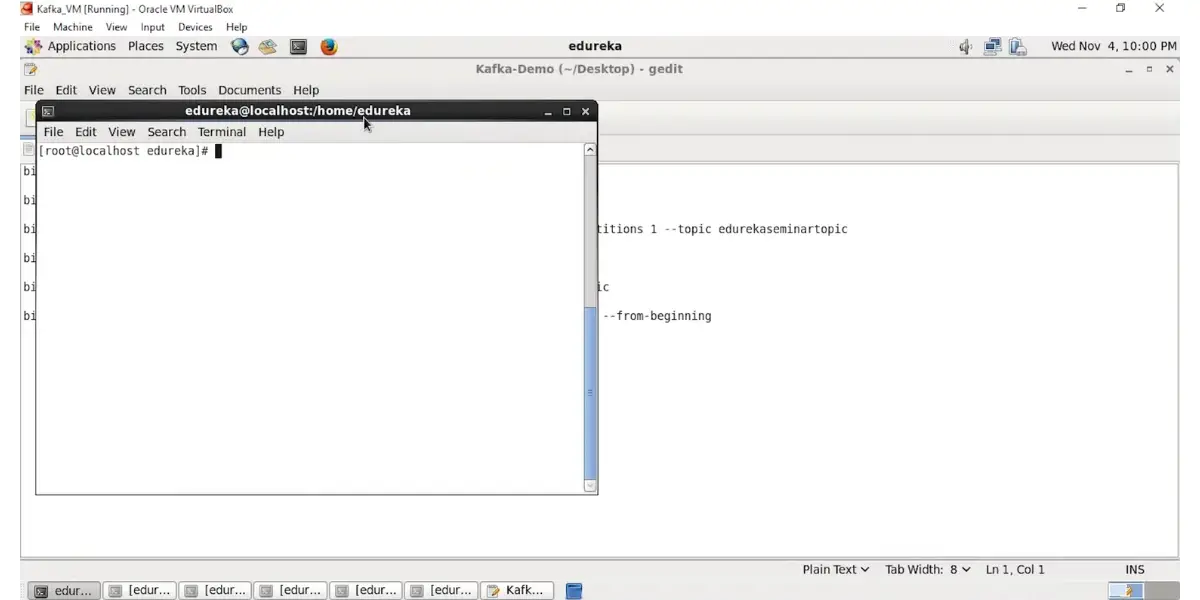
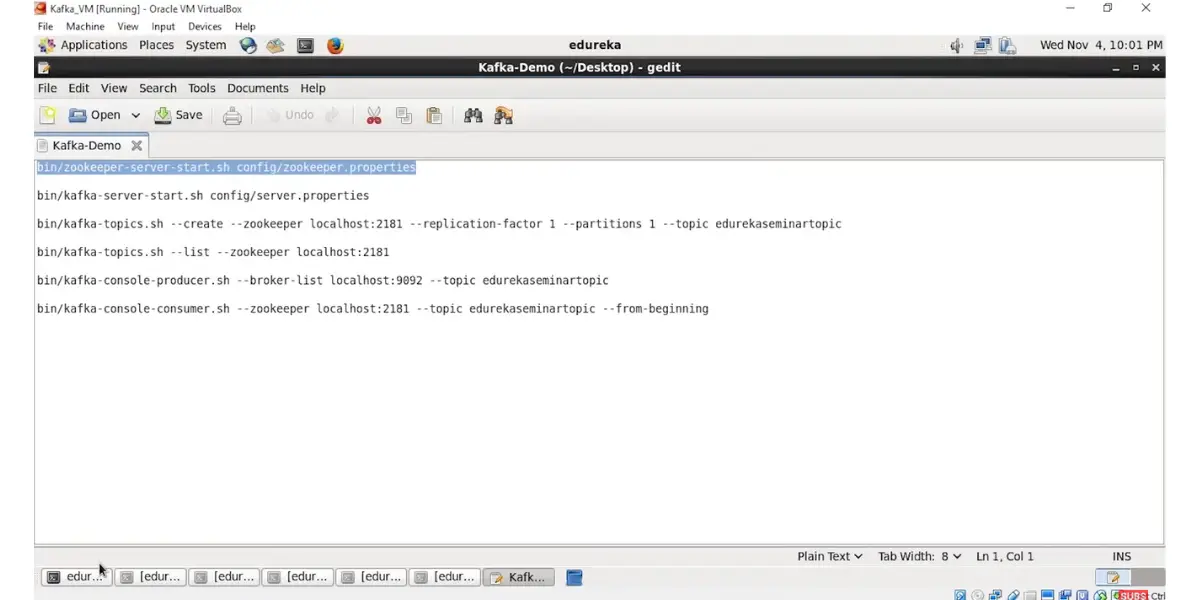

Implementation of Kafka
The following implementation steps will guide you to start with Kafka.
- Download Kafka: Download the latest release.
- Start Kafka environment: It can be started using Zookeeper or KRaft.
- Create a topic to store events: This powerful platform for distributed event streaming offers the ability to read and write events seamlessly across many machines.
- Write an event to the topic: The Kafka client works tirelessly to bridge the gap between your applications and a network of resilient brokers, safely storing events you need for as long as you desire.
- Read the event: It allows for unlimited replayability and verification of events. Start another terminal session to instantly access the same data previously stored in Kafka.
- Import and export data: With Kafka Connect, we can easily move data between files and topics for smoother import/export operations.
- Process event with Kafka: Building real-time applications and microservices is now easier with Kafka Streams – the Java/Scala client library. With it, you can quickly store data as events.
The above steps need to be followed quickly; if you want to stop the procedure, use ctrl-c.
Other details
| APIS | Procedure API, consumer API, streams API, connect API, Admin API. |
| Configuration | Broker configuration, topic configuration, producer configuration, consumer configuration, connect configuration, streams configuration, AdminClient configuration |
| Designs | Motivation, persistence, efficiency, the producer, Consumer, message delivery semantics, replication, log compaction, quotes. |
Who can use Kafka?
IT operations
Apache Kafka is an ideal companion for IT Operations that need to stay informed. From website tracking and log management to alerting, reporting, and monitoring, It gives us the information we need to know what is happening around us.
Internet of things
IoT generates enormous data that Apache Kafka is designed to scale effectively and process, giving businesses unprecedented access to actionable insights.
E-commerce
Apache Kafka is revolutionizing e-commerce, making it simpler and more efficient than ever. Through its data processing capabilities, businesses can track everything from customer preferences (e.g., page clicks or likes) to orders, shopping carts, and inventory levels – all in one place.
Pros and cons of Kafka
 Pros
Pros
- High throughput
- Low latency
- Fault-tolerant
- Durability
- Scalability
- Massage broker capacities
- Distributed
- High concurrency
- Consumer-friendly
 Cons
Cons
- Not support wildcard topic selection
- An issue with massage tweaking
- Lack of monitoring tools
- Logging is a little confusing
- Broker and consumer patterns may reduce the performance
FAQs
How Kubernetes scales apache kafka operations?
Kubernetes is a good platform to use for Apache Kafka. Developers need a platform that can be scaled up or down easily to host Kafka applications, and Kubernetes can do that. In addition, Apache Kafka in Kubernetes makes it easy to deploy, configure, manage, and use Apache Kafka.
Conclusion
To conclude, it is clear that Apache Kafka is an efficient and sophisticated data streaming software that simplifies data storage tasks.
It offers the scalability and robustness needed for modern enterprise systems. Moreover, its low latency enables businesses to respond quickly to customer needs with minimal system cost.
This post has detailed the advantages of using Apache Kafka for your data storage needs and provides sample use cases, implementation details, and user information so you can make an informed choice.
With all these features, Apache Kafka is becoming increasingly popular and will continue to as long as its revolutionizing features come in handy.
Reference