
In today’s business world, you should be able to make quick decisions based on accurate information, and that’s not possible if you’re struggling with data management issues.
Data fabric offers a solution to your data management problems. With this platform, you can easily collect data from any source, manage it effectively, and analyze it to get the insights you need to make informed decisions.
In this blog post, we will study the definition of data fabric, its architecture, examples, benefits, and implementation. We will also look into the difference between data fabric and data lake.
What is a Data Fabric?
A data fabric is like a super-smart system that helps different data pipelines and cloud systems work together seamlessly. It’s really important because the past decade has seen a huge explosion in big data, thanks to things like hybrid cloud, artificial intelligence, the Internet of Things (IoT), and edge computing.
But all this data growth has created problems like data silos, security risks, and slow decision-making.
So, data management teams are using data fabric solutions to fix these issues. They use data fabric to bring all their different data systems together, make sure everything follows the rules (governance), keep things safe, and make data easier for everyone to use, especially people in the business. It’s like a data superhero for modern businesses.
It is a term used in data management to describe a distributed database that gives a single point of control to manage data across multiple servers.
It is a collection of integrated technologies that provide a unified data management platform that includes databases, data warehouses, and analytic tools.
Example
An example of data fabric is a Hadoop Distributed File System (HDFS) to store and process data. Here data is distributed across servers in a cluster, and HDFS enables parallel data processing. That reduces the processing times compared to data processed on a single server.
Another example would be the Microsoft Data Platform, a collection of integrated technologies that provide a unified data management platform. It includes databases and data warehouses to big data platforms and analytic tools.
Architecture
Data fabric architecture is a comprehensive framework designed to address the complexities of managing and utilizing data in modern enterprises.
It provides a unified and intelligent solution to the challenges arising from the exponential growth of data, hybrid cloud environments, artificial intelligence, the Internet of Things (IoT), and edge computing.
This is built on the Hadoop Distributed File System (HDFS) and uses Apache Spark for in-memory processing. In addition, it integrates with other enterprise data management solutions, such as IBM InfoSphere BigInsights and IBM InfoSphere Streams.
Data Fabric Architecture consists of eight key components:
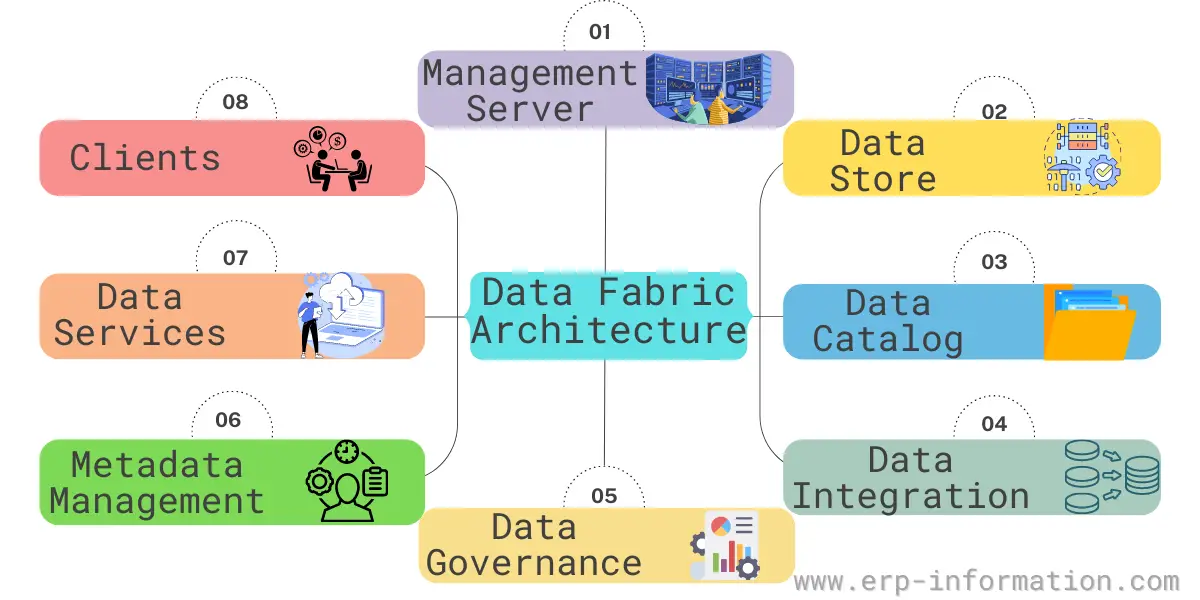
Management server
This server manages all other servers in the system and is responsible for executing tasks such as provisioning, monitoring, and troubleshooting. It also stores system configuration information and handles user authentication.
Datastore
This is where data is physically stored. The data storage type depends on the data fabric’s specific implementation.
For example, some common data stores include a file system, a relational database, or a NoSQL database.
The data catalog
It includes information about the data, such as its location, format, and owners. The Data Catalog also provides metadata about the business processes that use the data.
Data integration
Data integration combines data from multiple sources into a single repository. That ensures that all data is available in one place, making it easy to access and analyze.
Data governance
Data governance ensures that all data complies with corporate standards and best practices. That helps to ensure that all data is high quality and consistent across the organization.
Metadata management
Tracks and manages metadata associated with data assets. That helps ensure that all relevant information about a given asset can be easily accessed and updated.
Data services
These services act on data in the data store. They can be used to manipulate or query data or to load it into or out of the store.
Clients
These are applications that access data in the store through the data services.
Some other components are
Automation and Intelligence
Data fabric architecture often incorporates intelligent features and automation. This can involve using artificial intelligence and machine learning to optimize data processes, detect anomalies, and improve decision-making.
Scalability
The architecture should be scalable to adapt to changing data needs. It can grow with the organization, accommodating increasing data volumes and new data sources.
Cloud Integration
As cloud services play a significant role in modern data management, data fabric architecture is designed to seamlessly integrate with various cloud platforms, enabling businesses to leverage the benefits of cloud services.
Implementation steps
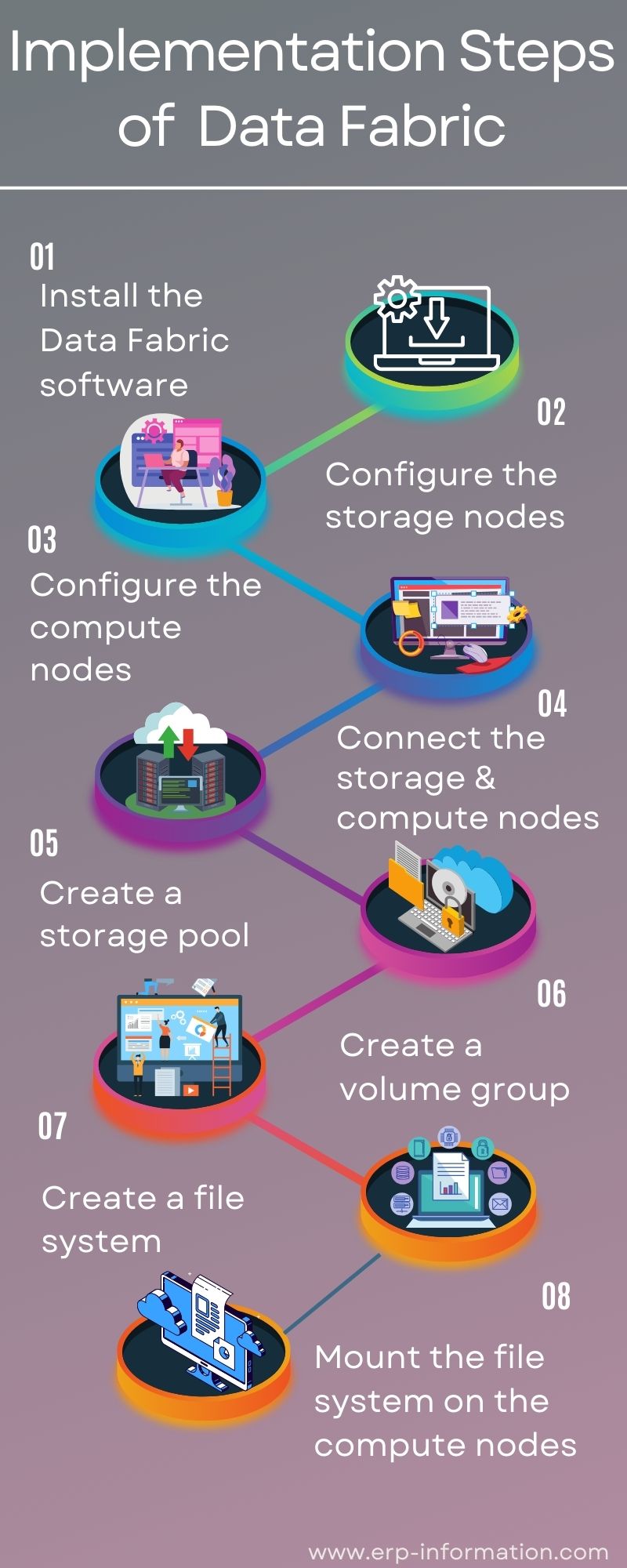
- Install the software: It can be installed on-premises or in the cloud.
- Configure the storage nodes: It uses a variety of storage nodes like the file system storage node, the object storage node, and the HDFS storage node that can be configured to store data in different ways.
- Configure the compute nodes: It uses various compute nodes like the data node, the application node, and the edge node. Those can be configured to run different applications.
- Connect the storage and compute nodes: This uses a variety of connectors to connect the storage and compute nodes.
- Create a storage pool: Uses storage pools to aggregate the storage from multiple nodes into a single logical pool.
- Create a volume group: Software uses volume groups to aggregate the storage from multiple nodes into a single logical volume.
- Create a file system: The system uses file systems to store data in a hierarchy of directories and files.
- Mount the file system on the compute nodes: The file system can be mounted on the compute nodes to make it accessible to applications.
Benefits
There are many advantages to using this system in your business, the benefits are as follows:
Increased efficiency
It enables businesses to quickly and easily connect their data, regardless of where it is stored or structured. That reduces the time and resources needed to integrate new data sources, which can help increase efficiency across the organization.
Improved agility
It helps improve the skill by allowing businesses to easily add new data sources as needed. That allows companies to quickly adapt to changing needs or requirements, which can help improve operational efficiency and competitiveness.
Reduced costs
It helps reduce costs by eliminating the need for expensive dedicated hardware or software for each new data source. Instead, businesses can use existing infrastructure to support new data sources, which can help lower costs overall.
Creates data backup
It can also help companies keep track of their customers and employees and what they buy. In addition, it can store data in the cloud or on a company’s servers and create a data backup to restore it if lost.
Data Fabric vs Data Lake
| Data Fabric | Data lake |
| Designed to keep both unstructured and structured data | Typically store unstructured data |
| Designed for more complicated operations such as machine learning and artificial intelligence | Typically used for analysis and reporting. |
| This allows users to continue working with the source data without pre-processing it. | Provide a storage area for data that has been cleaned and formatted |
| Typically deployed in the cloud | Data lakes can be deployed on-premises or in the cloud |
| To be more scalable | Less scalable |
FAQs
What is data fabric networking?
Data fabric is designed to allow devices to communicate instantly without a central server. That results in faster and more efficient data transfers and can also help to improve overall network performance.
In contrast, traditional networking architectures are based on a centralized model in which all data is routed through a central server or switch. That can create bottlenecks and lead to inefficient use of resources.
What is open source data fabric?
It is a type of data management software that allows you to manage and process your data across multiple servers.
It provides a way to move and collect your data, allowing you to quickly and easily take advantage of big data technologies. This also helps to ensure the security and integrity of your data.
What are the five best data fabric tools?
Hadoop Distributed File System, Microsoft Data Platform, DataStax Enterprise, Cloudera, and IBM Bluemix Data Services.
What is the main reason for adapting data fabric?
Data fabric is the key to unleashing the full potential of data within your organization. It simplifies data management, making it flexible and scalable.
It ensures seamless handling of diverse data types from various locations, maintains data access consistency, empowers self-service, enforces governance, and automates data integration.
What are the capabilities of data fabric?
Consistency Assurance: Data fabric ensures that data remains consistent across various integrated environments, preventing discrepancies and errors.
Automation: It reduces manual, time-consuming tasks through automation, making data management more efficient.
Accelerated Dev/Test and Deployment: Data fabric speeds up the development, testing, and deployment of applications, leading to faster innovation and adaptation.
Continuous Protection: It safeguards your data assets around the clock, 24x7x365, providing reliable data security and backup.
In simple terms, data fabric makes sure your data is the same wherever it’s used, automates tasks, speeds up creating and launching new stuff, and keeps your data safe all the time.
Conclusion
Suppose you are looking for a way to manage and process your data. In that case, data fabric may be the right solution for you.
It provides a way to move and collect your data, allowing you to quickly and easily take advantage of big data technologies.
It also helps to ensure the security and integrity of your data. As a result, it is a powerful tool that can help you consolidate your data, improve performance, and scale your business.