
Imagine a huge library where every bit of information your business needs is neatly organized, and ready for instant access. That is the data warehouse. It is a powerhouse that doesn’t just store data but transforms it into golden insights for smarter, more strategic decision-making.
A data warehouse is a great way to store your data, so it’s easy to access and analyze. It’s perfect for businesses that want to make better decisions using their data.
The blog will discuss data warehouse definition, features, working, architecture, and types. It will also explore its benefits, disadvantages, tools, and ERP data warehouse.
Data warehouse definition
A data warehouse (DW) is a data repository structured for reporting and analysis. It usually contains historical data that has been cleansed and transformed to meet the needs of the business.
Business Intelligence (BI) tools often use it to allow users to perform complex data analyses. BI tools can include reporting tools, OLAP cubes, and dashboards.
Features
- It is a system that stores “big data.”
- It’s used to store and manage large amounts of information about business operations.
- An information warehouse aims to provide fast access to the most relevant information for decision-making.
- It can be created using a relational database management system (RDBMS) or an online analytical processing (OLAP) tool.
- RDBMS includes MySQL, Oracle Database, and Microsoft SQL Server; examples of OLAP tools include Cognos TM1 and Hyperion Essbase.
- They are sometimes called enterprise data warehouses because they help companies make decisions at all levels of the organization.
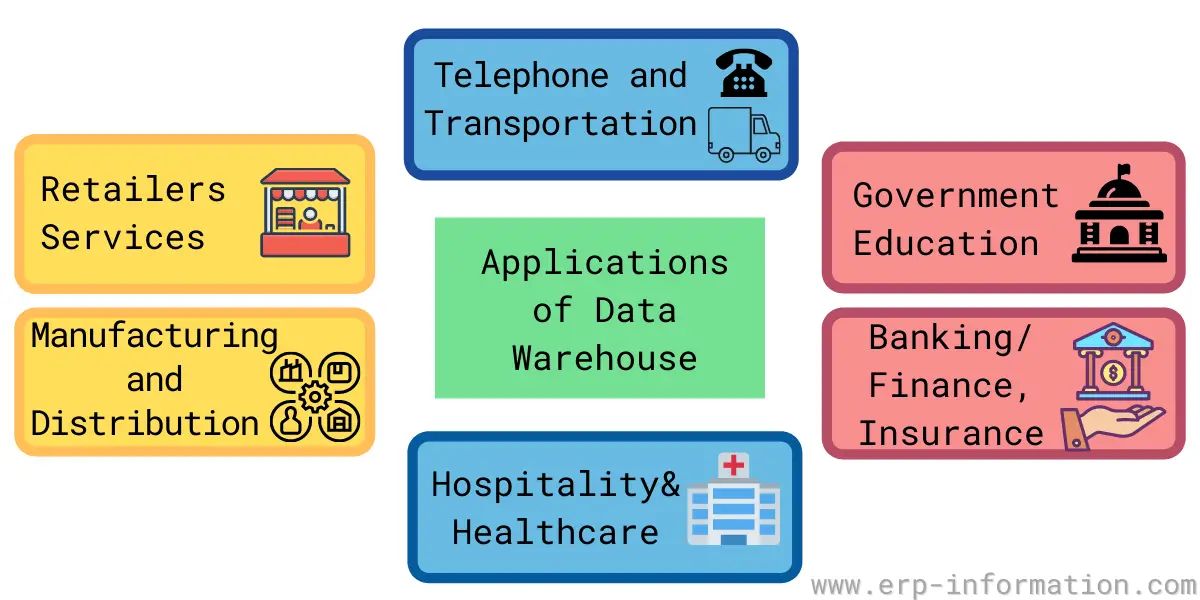
Where is it used?
It is used for reporting and analysis. It stores old data and also uses real-time data to generate business reports.
Below are the familiar sectors where the DW is used.
Public region
DW collects intelligence in government offices in this area. It also monitors and analyzes each individual’s health and tax records in government offices.
Bank sector
DW helps the banking sector control and investigate available resources on desks.
Hospitality industries
DW helps these industries to promote themselves and attract target customers.
Health care
In this area, the warehouse helps to generate patient treatment reports.
Airlines
Here, the warehouse analyzes the work assigned to the airline crew.
Insurance
In this sector, the warehouse helps trace market fluctuations.
Levels of DW and their working
It comprises several levels. A few of them are mentioned below:
Data Source Layer
The first level, the data source layer, involves gathering data from various sources, such as operational databases or external sources. This layer is important for collecting and integrating large amounts of data from multiple sources.
Data Extraction Layer
Next, in the data extraction layer, this raw data is transformed and cleaned before being moved to the staging area.
Staging Area
The staging area is where raw data from various sources is cleansed and transformed before being loaded into the data storage layer.
ETL Layer
Next, it undergoes further processing in the ETL (extract, transform, and load) layer before being stored in the data storage layer.
Data Storage Layer
The data storage layer is where the actual warehouse data is stored and managed using a combination of relational databases, cubes, and files.
Data Logic Layer
In the next level, the data logic layer, the information is organized and structured for easy access by decision-makers. That may involve utilizing data analytics and data management tools to analyze and manipulate the information.
Data Presentation Layer
The seventh level, the data presentation layer, involves presenting this processed information to users through a central repository or dashboard interface. Again, advanced machine learning technologies can be utilized in this stage for enhanced analysis and insights.
Metadata Layer
The metadata layer holds information about the structure and content of the data in the warehouse, including source systems, definitions, relationships, and transformations applied to the data.
System Operations Layer
The system operations layer manages and monitors the technical aspects of the warehouse, such as access control, backup, recovery, performance tuning, and overall system health.
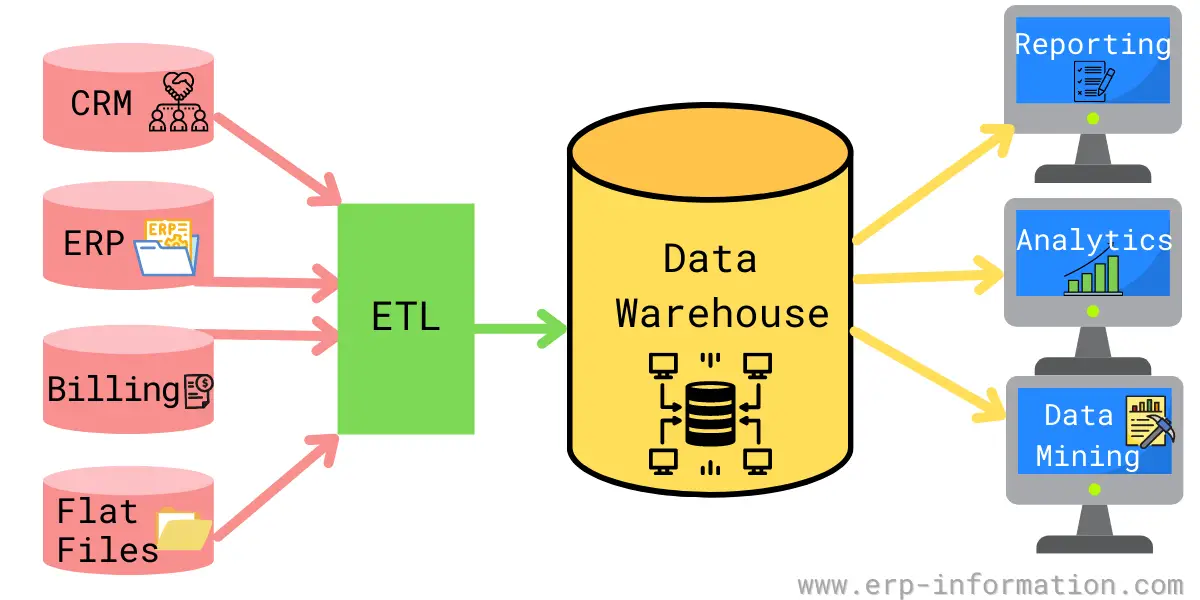
Data warehouse architecture
There are three types of architecture in it.
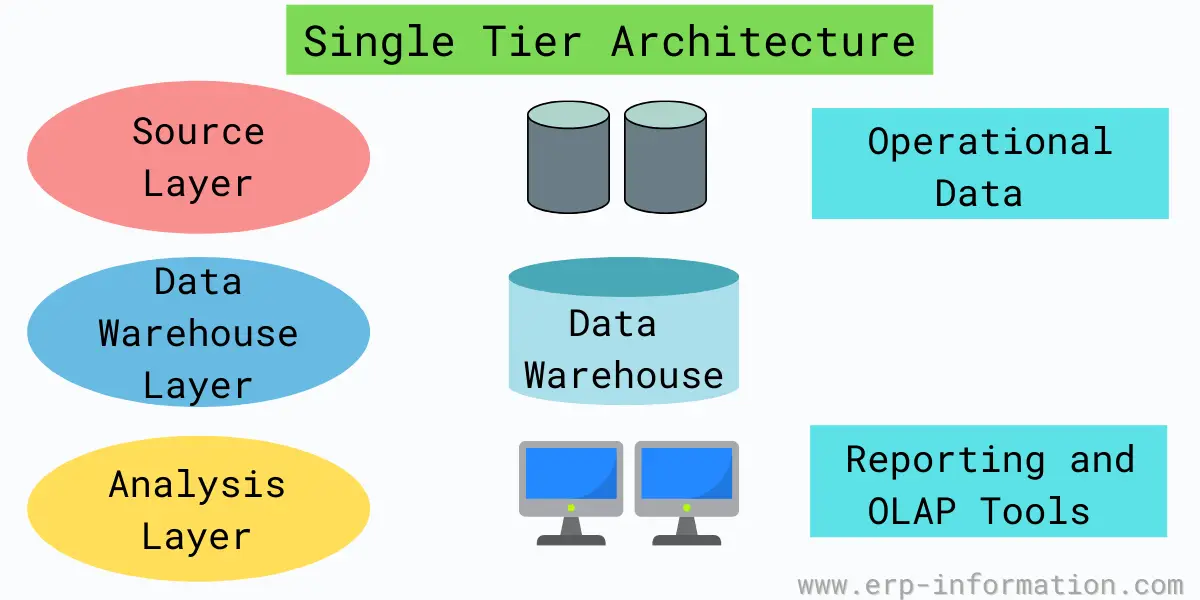
1. Single-tier architecture
It is rarely used architecture. It reduces the amount of data stored by avoiding repetition.
In this type of architecture, only the source layer is available. Thus, the single-tier consists of the source, data warehouse, and data analysis layers.
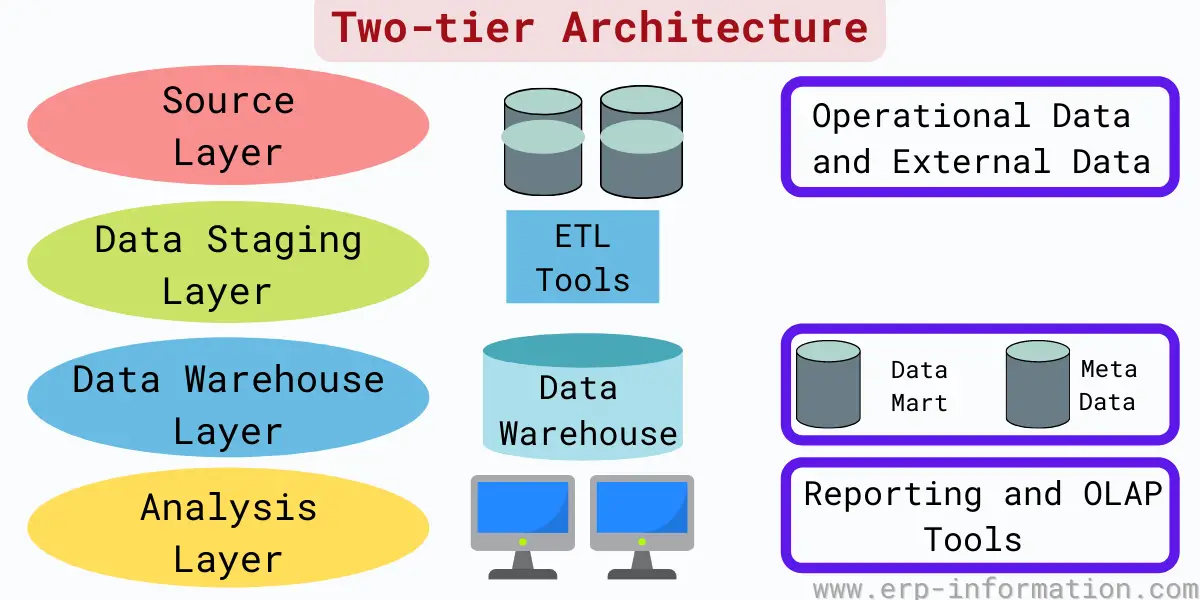
2. The two-tier architecture
It consists of a data staging area or ETL (extraction, transformation, and loading) and the source layer.
This layer helps to merge diversified data into one standard schema. This type of architecture consists of the source layer, data staging layer, DW layer, and analysis layer.
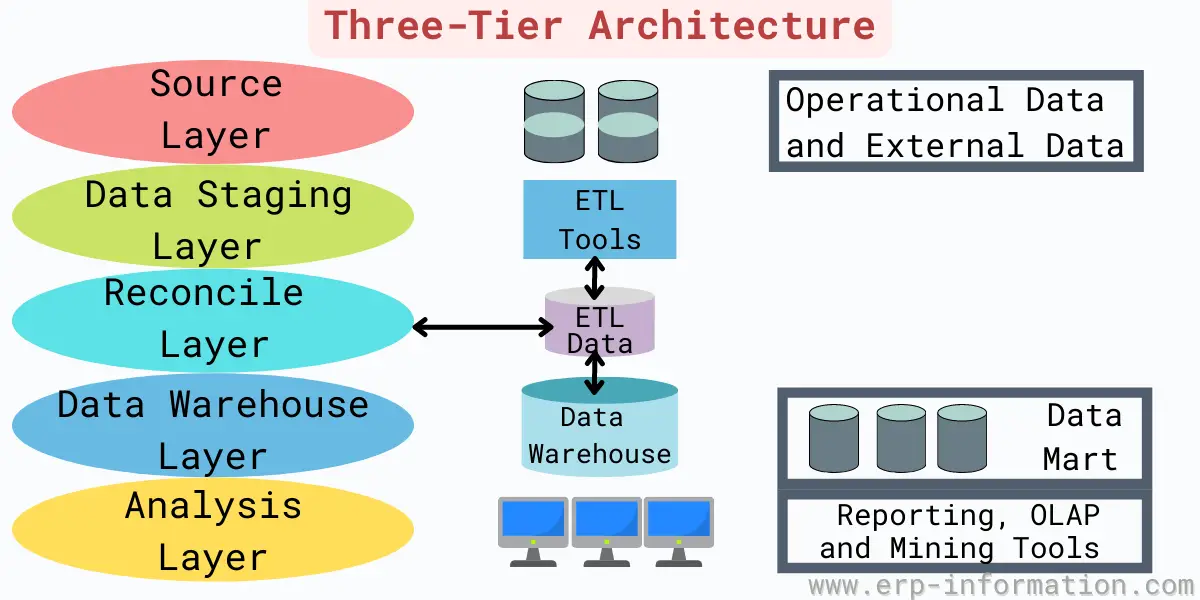
3. The three-tier architecture
It contains a reconciled layer and the data staging and source layer. The source layer contains multiple sources in this architecture.
The role of a reconciled layer is to generate a standard data model for the entire enterprise. This reconciled layer can also be used to do some operational works like reporting.
This architecture consists of the source, data staging, reconciled, data warehouse, and analysis layers.
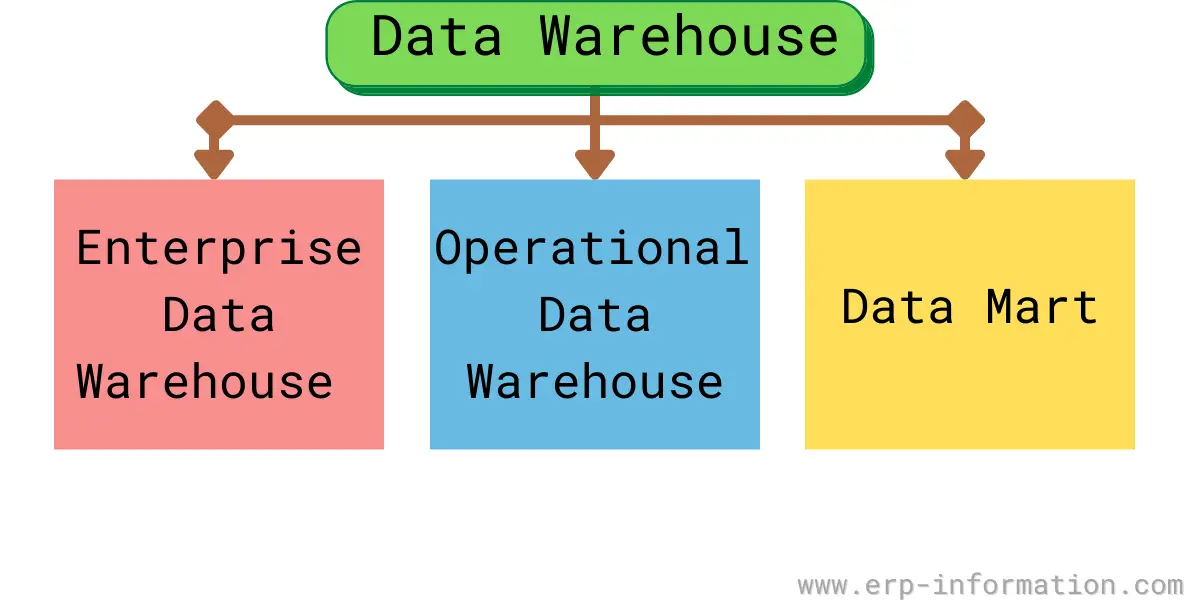
Data warehouse types
1. Enterprise Data Warehouse (EDW): It helps to provide decision support services throughout the enterprise and also helps to classify data according to the subject.
2. Operational Data Store: It helps to store records of employees.
3. Data Marts: It helps to collect data directly from sources.
Relationship between data warehouse, database, and data lake
| Data warehouse | Database | Data lake |
| It is responsible for storing data extracted from multiple sources, including operational systems and external data sources. | It is a collection of information organized specifically by one or more applications. | It is a big storage repository where the data is stored in its original format without any predefined schema. |
There are several potential relationships between these three types of data stores:
- A data warehouse can be used as the source for the data loaded into a data lake.
- The data in a data warehouse can be periodically extracted and loaded into a data lake.
- The contents of a data lake can be copied (or replicated) into a database.
How can a data warehouse benefit an organization?
1. Subject-oriented
A specific business purpose can be analyzed with the data collected here.
Suppose the business wants to understand the machine downtime and how it can be reduced. In that case, data can be collected from the warehouse to understand the various times or situations during which the machines stopped working, the reasons behind the same, and how this can be reduced.
2. Integrated
Data from different sources are integrated to provide cooperative data. For instance, if a company wants to do budgeting for the next quarter, a warehouse will have all the information required.
The entire data set is available in one source, from incurred to depreciation costs.
3. Time-variant
The company utilizes the historical data stored in the system to extract relevant reports and understand the overall organization’s health.
But data such as the employee database, which includes addresses and phone numbers, must not be included as they are subject to change.
4. Non-volatile
Once data is entered, it remains the same. Therefore, the firm must ensure that information is highly protected and that there is no alteration.
If any modifications are made, it will affect the reports and analysis.
5. Improved data quality
It helps to improve data quality by providing consistent, accurate data and fixing insufficient data.
Disadvantages
Cost v/s Benefit
It is an IT project that consumes more person-hours and more money from the budget. Moreover, its implementation and maintenance are costly.
Hence the cost-to-benefit ratio is meager. However, if the organization is small or medium, it may affect its revenue.
Data Ownership
We know that warehouses are software applications for service. Its primary concern of it is the security of data.
You have to be more sure that the people who handle and analyze the customer data are the employees that your company trusts.
Because leaking the customer’s data within the organization may cause problems for executives and affect the relationship between the company and the customer.
Data Rigidity
The data imported into the DW is often a static data set that has less flexibility. They have less ability to generate a particular solution.
Warehouses are subjected to ad hoc queries that are highly difficult due to their most minor processing and query speed.
Miscalculation of ETL Processing Time
The entire warehouse development process, such as the extraction, cleaning, and loading of consolidated data into the warehouse, takes more time.
But usually, organizations do not guess the time required for the ETL process. As a result, it leads to a backlog of work.
Data warehouse vs database
| Database | Data warehouse |
| Collects data for multiple transactions | Transfers and stores accumulated data for analytical purposes |
| Developed for write or read access | Developed for the accumulation and recapture of large data sets |
| Made for quick recording and recapture of data | Made for a more straightforward analysis of data collected and stored from multiple databases |
History
In the 1950s American government and businesses started using punch cards to store computer-generated data. They were being used till the 1980s.
In the 1960s, slowly disk storage systems came into the picture, and in 1964 the systems became popular, called ‘magnetic storage’ for data.
IBM was the first company that designed and started using the floppy disk drive. Later is called the hard disk drive.
In 1966, IBM designed its DBMS (database management system) called the ‘information management system.’ It contained the following features.
- Ability to find out the exact location of data
- Ability to solve the problem of locating more than one unit of data in the same place
- Ability to delete data
- Ability to access the data rapidly
- Ability to allocate the place when data stored cannot fit in the specified location.
In 1970, online applications came into the picture. People know that data can be directly accessible and shared between computers.
After that, people started using their personal computers. It changed the way of doing work. At the same time, 4GL technology was invented.
The combination of personal computers and 4GL technology gave complete freedom to the end user. It allows end-users to access their data efficiently and rapidly by controlling the computer system. But they found the following problems.
- They got misled by incorrect data.
- Old data is not at all useful
- Confusion because of duplicated data
As a solution to these problems, the rational database was used in the 1980s. It used SQL (structured query language)as its language.
Businesses started assigning personal computers to employees and widely used office applications (MS Word, MS Excel, MS Office).
In the year 1990, significant changes took place. That is the usage of the internet. The Internet became very popular, and conflict started because of globalization, computerization, and networking.
In 2000, businesses needed good integration between systems and consistent data to get the accurate business information required for proper decision-making.
Because of expanded databases and application systems, getting consistent data became difficult. Hence a data warehouse is developed by businesses.
Data warehouse tools
- QuerySurge
- Oracle
- Amazon Redshift
- Microsoft Azure
- CData Sync
- Snowflake
- SAP HANA
- Teradata
- SAS
- MarkLogic
- Amazon RDS
- Amazon S3
- Maria DB
- Exadata
- Cloudera
- Google BigQuery
- Micro Focus Vertica
- Amazon DynamoDB
- PostgreSQL
- Oracle Autonomous Warehouse
ERP data warehouse
ERP systems serve as the backbone of an organization, consolidating various business processes into a centralized platform. However, they often face limitations in handling extensive data analytics or historical trend analysis due to their transactional nature.
The data warehouse is a dedicated repository designed for storing, organizing, and analyzing vast volumes of data. Using an ERP system for data warehousing can significantly enhance an organization’s data management and decision-making capabilities in the following ways.
Strong warehouse management capabilities
Implementing an ERP data warehouse offers an array of pre-built, robust warehouse control functions that are readily available upon integration. These functions encompass various aspects of warehouse management, including inventory control, order processing, and logistics.
Adaptable backend for tailored parameter customization
One of the standout advantages of an ERP data warehouse is its highly configurable backend. This customization capability allows organizations to tailor the system to their specific requirements.
Superb user-friendliness and easy access
User experience is pivotal in driving adoption and maximizing the benefits of any system. An ERP data warehouse offers an intuitive, streamlined interface designed for user-friendliness and accessibility. The simplified design facilitates easy navigation and interaction, enabling employees at various levels to engage with the system effectively.
Expandable digital framework for future growth
Scalability is a crucial aspect of any technology infrastructure. An ERP data warehouse boasts a scalable digital architecture that accommodates the evolving needs of a growing organization.
Whether it’s an expansion into new markets, increased transaction volumes, or additional data sources, the system can seamlessly scale to handle greater complexities without compromising performance.
Strong integrated analytics
Integrated analytics features within the ERP data warehouse empower organizations with actionable insights. These analytics capabilities enable users to extract, analyze, and visualize data from various operational areas.
By leveraging built-in reporting tools, dashboards, and predictive analytics, businesses gain deeper visibility into their processes, uncover trends, and make data-driven decisions swiftly.
Extra functionalities covering diverse operational domains
Beyond warehouse management, an ERP data warehouse encompasses an extensive array of additional features that span various operational domains. These encompass financial management, human resources, sales and marketing, procurement, and more.
FAQs
What is the main difference between data warehouses and databases?
Data warehouses are designed for analytical purposes, storing vast amounts of historical data from multiple sources. They consolidate data to facilitate complex analysis, reporting, and decision-making.
Databases are designed primarily for transactional purposes, handling day-to-day operations and transactional data storage.
Conclusion
The data warehouse is a term that has been around for more than two decades. It is one of the most essential and powerful tools in modern business intelligence. It is the place where information becomes innovative.
We’ve explored its architecture, the diverse types available, benefits, limitations, and crucial distinction from databases. Remember, while databases store, data warehouses empower. They’re the catalysts for turning raw data into actionable insights that drive businesses toward unparalleled growth and informed decision-making.
Reference