
Choosing the right large-scale data storage tool is critical for success.
Apache ORC is a large-scale storage data tool with many features that can benefit your business. Some of its pros include performance and indexing. However, it has some cons, such as its learning curve and user interface.
This guide provides you with Apache ORC features, pros, and cons to determine if it’s the right solution for your organization’s needs.
Details about Apache ORC
In recent years, Apache ORC has become one of the most popular formats for storing large datasets in business and manufacturing.
It offers advantages over other data storage alternatives, such as Parquet, because it compresses columnar data efficiently and is compatible with various open-source technologies.
It is the fastest, smallest columnar storage for Hadoop workloads.
It is open-source software released under an Apache license. Its latest release uses JAVA and C++ reader and writer for ORC files.
Latest release: 2.0.0
Date: 08 March 2024
Features
- ACID Support – Serialization for operation is as follows
- 0 – Insert
- 1 – Update
- 2 – Delete
- Built-in Indexes – Three levels of indexes in each file
- File-level – Contains statistics about the values in each column across the entire file.
- Strip level – Contains statistics about the values in each column for each strip.
- Row level – Contains statistics about the values in each column for each set of 10,000 rows within a strip.
- Complex Types – Provides scalar and compound types
- Integer
- Floating point
- String types
- Binary blobs
- Decimal type
- Date/Time
- Compound types
Some screenshots of Apache ORC features
Table Creation
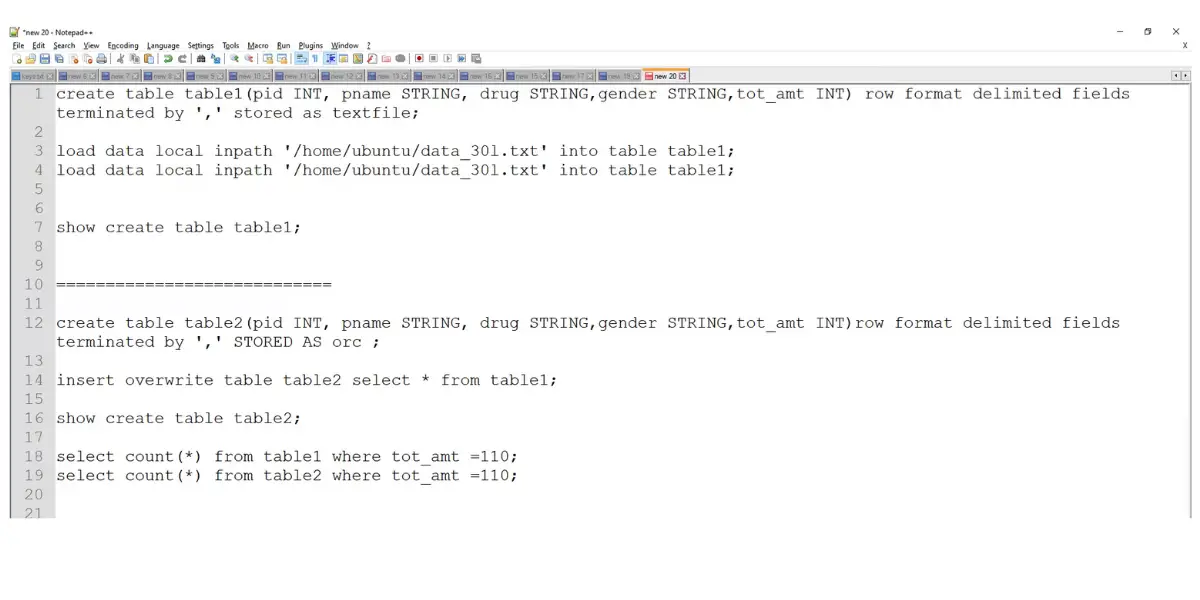
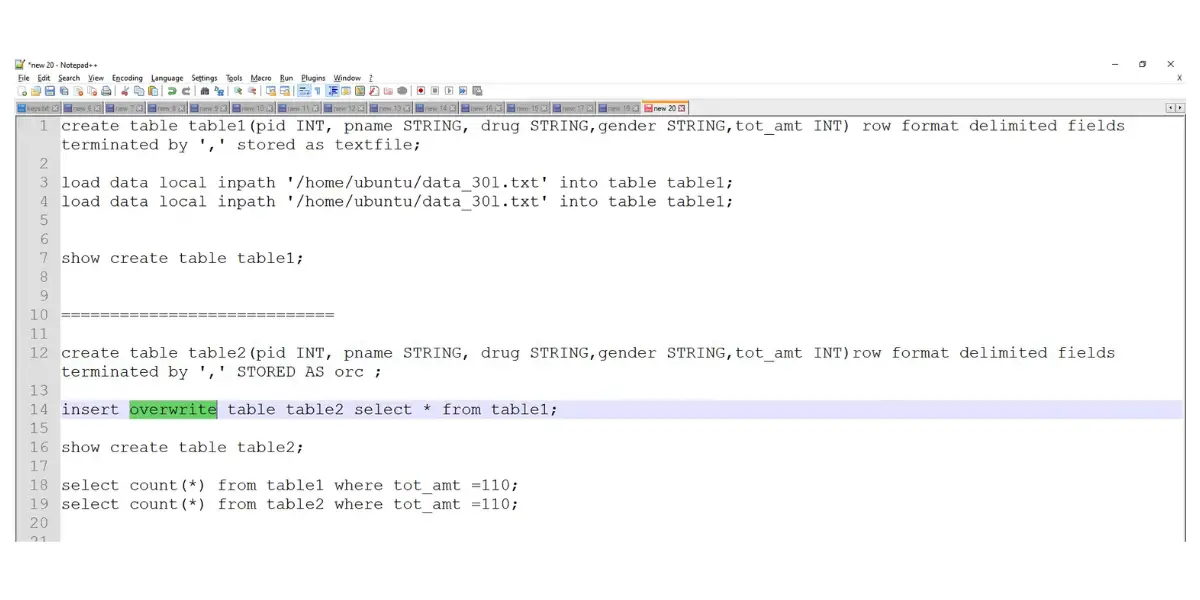
Overview of Processing Table Creation
Supported Languages
- Spark
- Python
- Hive
- Hadoop MapRed
- Hadoop MapReduce
- Java
Pros
- It contains built-in powerful and efficient indexing
- It provides maps, hive, and bloom filters
- Its response time is fast
- It provides drone analytic features
Cons
- The user interface could be more user-friendly
- It could be more stable. Its stability has to improve
- You will get confused till you get adjusted
- Its efficiency is less with nested data
Apache ORC vs Apache Parquet
Apache ORC and Apache Parquet are columnar storage formats for storing large amounts of structured data. Following are some key differences between the two.
- Both ORC and Parquet support compression, but they use different algorithms. ORC supports ACID characteristics, and its compression efficiency is higher than Parquet.
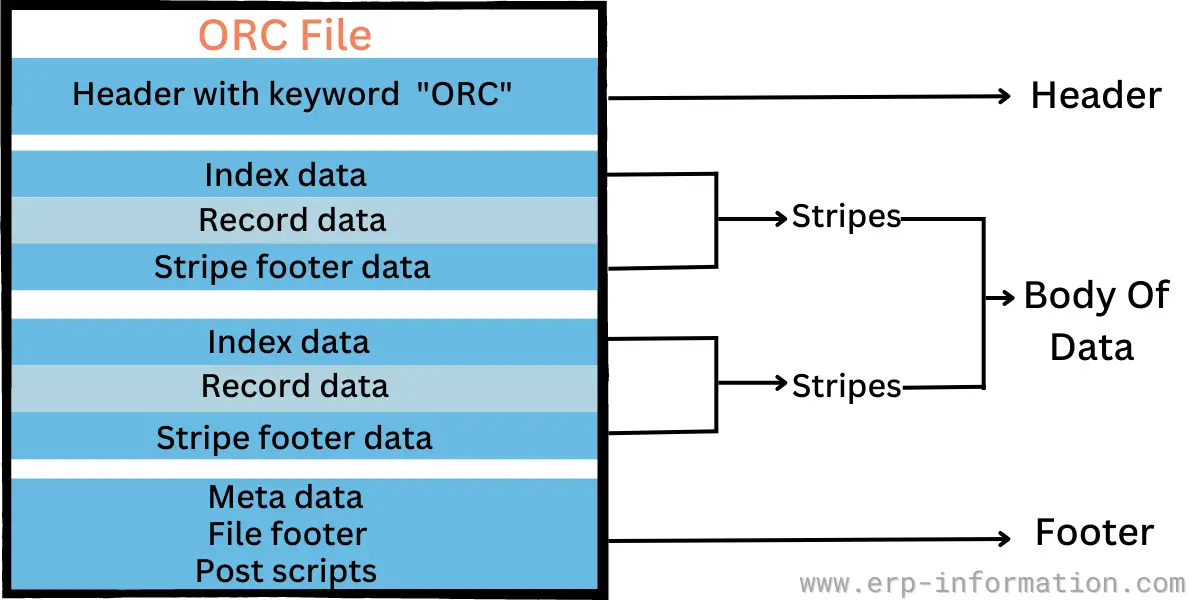
- Indexing is good in both ORC and Parquet. In ORC, files are organized with stripes. Each stripe contains an index, row data, and footer. Parquet organizes data with headers, definition levels, repetition levels, and data.
- ORC is less efficient with nested data, but Purquet is efficient in storing nested data.
- Both formats have strong support in the Hadoop ecosystem and can be used with tools like Hive, Pig, and Spark. However, ORC is more commonly used in Hive and pig-based systems. Parquet supports the Hadoop ecosystem and works well with Apache Spark.
- ORC supports multiple encoding schemes for each column, including dictionary, run-length, and delta. Parquet uses a similar approach but also supports bit-packing and other specialized encodings.
- Both formats offer excellent performance for read-heavy workloads requiring quick queries to scan large datasets. However, ORC performs better than Parquet regarding write-heavy workloads involving frequent updates or appends.
- ORC has better support for schema evolution than Parquet. It allows you to add or remove columns from a table without having to rewrite the entire dataset. In contrast, Parquet requires creating a new file whenever the schema changes.
Quick view of differences between ORC vs Parquet
| It supports bit-packing and other specialized encodings, dictionary encoding, run-length encoding, and delta encoding. | Apache ORC | Apache Parquet |
| Compression | Compression efficiency is high | Compression efficiency is low |
| Indexing | Files are organized with stripes. Each stripe contains an index, row data, and a footer. | It organizes data with headers, definition levels, repetition levels, and data. |
| Nested Data | Less efficient | More efficient |
| Hadoop Ecosystem | It is more commonly used in Hive and pig-based systems. | It supports the Hadoop ecosystem and works well with Apache Spark. |
| Encoding Schemes | It supports dictionary encoding, run-length encoding, and delta encoding. | It supports bit-packing and other specialized encodings along with dictionary encoding, run-length encoding, and delta encoding. |
| Schema Evolution | It provides better support. | It provides poor support. |
Overall, Apache ORC and Apache Parquet are highly efficient columnar storage formats that perform well for big data applications.
The below image shows indexing in ORC.
Conclusion
Apache ORC can be your best solution to increase effective data storage.
Its range of supported types and languages ensures that it can easily handle any database application involving fast read/write operations and scalability.
If you’re looking for an effective data storage solution from an established open-source platform, you might need Apache ORC. This article provided useful information regarding Apache ORC.
References