
You might be looking for the best machine-learning software. You should know about the different features of ML before choosing software to use data and algorithms.
Here we provide details about Scikit learn ML software so you can compare it with other software and make a better decision.
This blog post will provide information about Scikit learn software, its features, and pricing. Make sure not to miss this blog post by reading ahead until the end, where we discuss both the advantages and drawbacks of using Scikit learn AI technology.
What is scikit learn ML software?
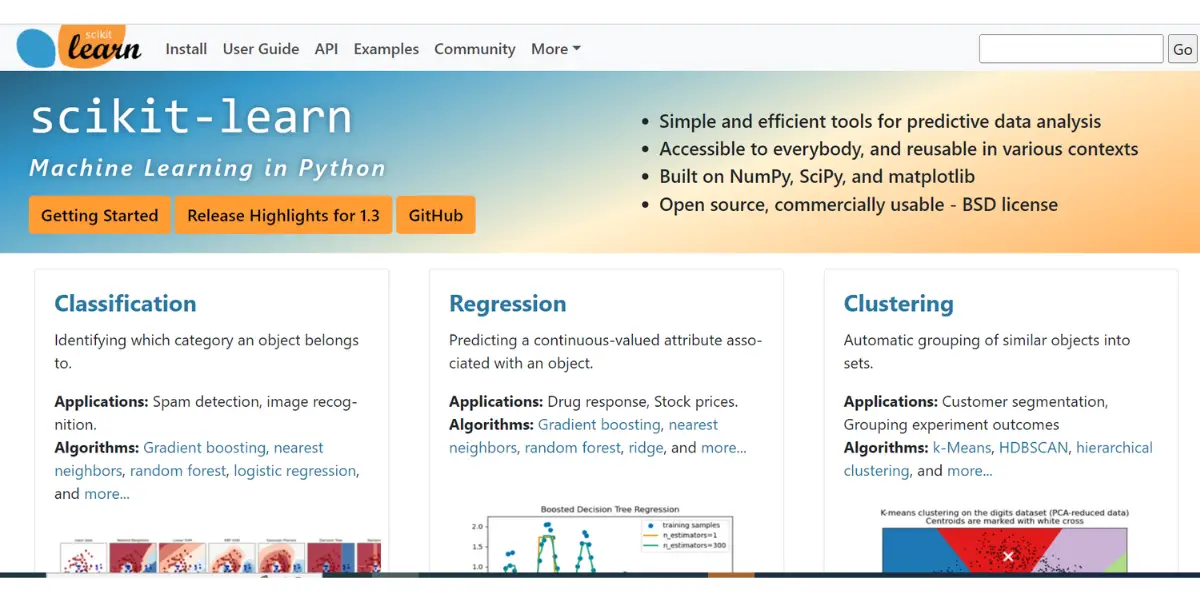
Scikit-learn is a machine-learning software library for the Python programming language. It features an easy-to-use API and supports various machine-learning algorithms. This made it ideal for both novice and experienced data scientists.
Installation Guide
- Choose the latest version of the stable version and pre-built packages
- Choose the version of your operating system or Python distribution
- Building the package from a source who prefers the latest features
- Installing on Apple silicon M1 Hardware
Third-party distributions of Scikit learn
Below are some third-party OS and Python distributions that integrate with Scikit learn and provide their version.
- Alpine Linux
- Debian
- Fedora
- NetBSDPorts for Mac OSX
- Intel conda channel
- WinPython for windows
For more information, you can refer to their Official website for installation.
Pricing
It is open-source software.
Features of Scikit learn
Inbuild dataset and learning algorithms
The datasets used in Scikit-learn are well-known and easy to understand. Therefore, you can directly implement machine learning models on them without pre-processing.
These datasets suit beginners as they understand the Scikit-learn library and its functions.
It features various classification, regression, and clustering algorithms, including support vector machines, logistic regression, naive Bayes, random forests, gradient boosting, k-means, and DBSCAN.
Split data set for training and testing
In Scikit-learn, we can define what proportion of our data will be included in train and test datasets. Splitting the dataset is essential for an unbiased evaluation of prediction performance.
For example, if we want to split our data into 80% train and 20% test datasets, we can use scikit-learn’s train_test_split function: from sklearn.
model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2). This will split our data into 80% train and 20% test sets.
We can then train our machine learning models on the training set and evaluate them on the testing set. Using scikit-learn’s built-in functions, we can easily split our data into train and test sets without worrying about doing it manually.
Cross-validation and extraction of features
This software is used for checking the accuracy and validity of supervised modules. This tool can also easily extract text, images, or video features!
Linear regression
A linear regression-supervised ML model is a powerful tool that can be used to predict future sales data.
The Scikit learn machine learning software can determine a linear relationship between the dependent and output variables by inputting sales data from previous months.
This information can then be used to forecast sales for the coming months. As a result, the linear regression supervised ML model is an essential tool for any business that wants to accurately predict future sales and make informed decisions about inventory and budgeting.
Logistic regression
The Scikit learn machine learning software can be used to train and test the logistic regression model. This feature is just like linear regression; only the difference is output variable is categorical.
Decision tree
Decision trees are useful when the dependent variables do not follow a linear relationship with the independent variable, i.e., linear regression does not have accurate results.
Here roots indicate that data splitting and node for output variable value. Scikit learn is a machine learning software used to generate a Decision tree.
Clustering and dimensionality reduction
The clustering feature allows for grouping the unavailable data. Finally, dimensionality Reduction allows you to reduce the number of attributes in your data. As a result, it is easier to visualize, summarize, and select features.
Bagging and boosting
The bagging feature is when training multiple models of the same type, you can use random samples from the training set. The inputs to the different models will be independent of each other.
However, if you want to boost multiple models of the same type, you can do so in a way that the input of a model is dependent on the output of the previous model.
Random forest
Random Forest is a technique that uses many decision trees to predict things. For example, it can be used to classify things (like whether someone is approved for a loan or not) and predict things (like how likely someone will get a disease).
Support Vector Machines(SVM)
Support vectors are the data points that are closest to a hyper lane. It can also be used for problems where you need to find how things change, like face detection or classification of mail; it’s used across many applications, such as recognizing people by their faces and sorting emails into categories like ‘spam’ with just one glance!
Some screenshots of scikit learn.
Other information
| Platform | Linux, Windows, Mac OS |
| Programming languages | Python, Cython, C, C++ |
Likes
- It is open-source and commercially usable.
- It is built on Numpy, Scipy, and MatPlotlib, which makes work easier.
- This is an easy-to-import and ready-to-use Python platform.
- The clarity, documentation, and versatility of this kit are appreciatable.
- Scikit learn comes in many different ML algorithms, which makes it easy to use.
- Sample datasets available for ML trial.
- It has been used in several real-world applications, including predicting the outcomes of elections and detecting fraudulent credit card transactions.
Dislikes
- Lack of deep neural network modules.
- This software is comparatively less capable of categorical variable transformation.
- It has no support for GPU computing.
- It runs slow on large datasets.
Alternatives
- TensorFlow
- Anaconda
- PyTorch
- Weka
- Google Cloud AI platform
- Amazon Personalize
- Apache Mahout
- Amazon Sagemaker
Conclusion
Scikit learning can be used for various tasks, including regression, classification, and clustering. As a result, it has many advantages over other machine-learning software packages.
After reading this blog, you should better understand what Scikit-learn is and how it can be used in your machine-learning projects.
You should be sensible of some potential drawbacks so that you can make an informed decision about whether or not it is the right tool for your needs.
Reference