
Do you want to store your data efficiently and safely? If yes, then the Parquet data storage system is your solution.
Parquet offers uncompromising performance in speed and reliability with cost-efficient storage capacity, making it one of the best choices when managing large volumes of data.
It organizes structured data into columns allowing quick scans and filter operations without sacrificing security or scalability.
In this post, we will discuss Parquet’s features, theory, types, advantages, disadvantages, and uses cases.
New version:1.12.3
Release date: May 2022
A Better Understanding of Parquet
Apache Parquet is a revolutionary, open-source data file format designed to maximize efficiency and performance for managing complex data.
It offers sophisticated compression techniques and encoding support in multiple languages like Java, C++, Python, and more – making it an optimal choice for bulk storage of large datasets!
Organizations in the big data world widely use it to store and analyze their data efficiently and cost-effectively.
This software offers many advantages over traditional row-based storage formats, including enhanced scalability, performance, and security.
With its easy integration with popular big data frameworks like Hadoop and Spark, Parquet makes it easy to query large datasets quickly and efficiently.
Features
Run length and dictionary encoding
This software saves space on your computer by not storing the same value many times.
Parquet lists how many times the value appears in a column. This saves a lot of space, especially when values are repeated often. For example, if you are monitoring CPU usage, every value will be between 1 and 100 percent utilization.
Record shedding and assembly
This software uses a technique from Google’s Dremel paper. This technique allows Parquet to map nested data structures to a column-based layout.
The benefit of this is that developers can still treat their data in a more natural nested style while getting the performance benefits of a column-based data structure.
Rich metadata
Parquet is a system that stores data in a certain way. This data is broken into row groups, column chunks, and pages. A file can have several row groups.
Each row group has one column chunk for each column. Therefore, each column chunk has one or more pages of data. This is complicated, but developers don’t need to worry about it directly.
Language agnostic
Apache parquet’s Language Agnosticism helps to create abstract data types and functions that have no dependency on any one coding language but rather work across many different ones.
For example, if you’re writing a program in Python, you’ll want it to be as generic as possible to run within Python and in Java or C++ if needed.
some screenshots of Parquet feature
Overview of Parquet coding
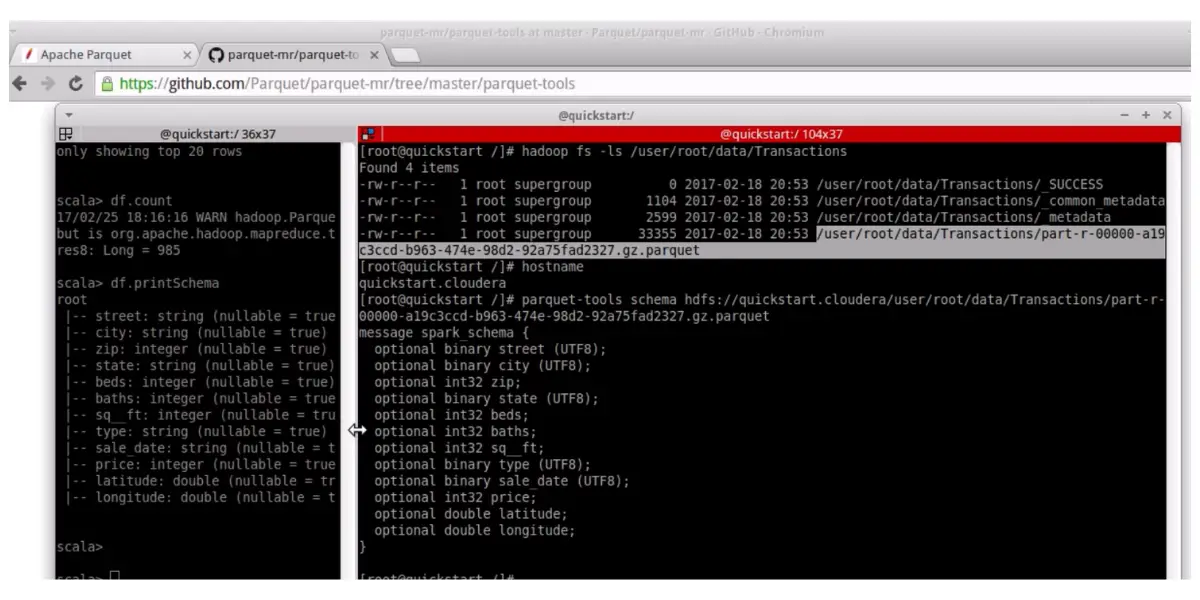
Parquet street list Working
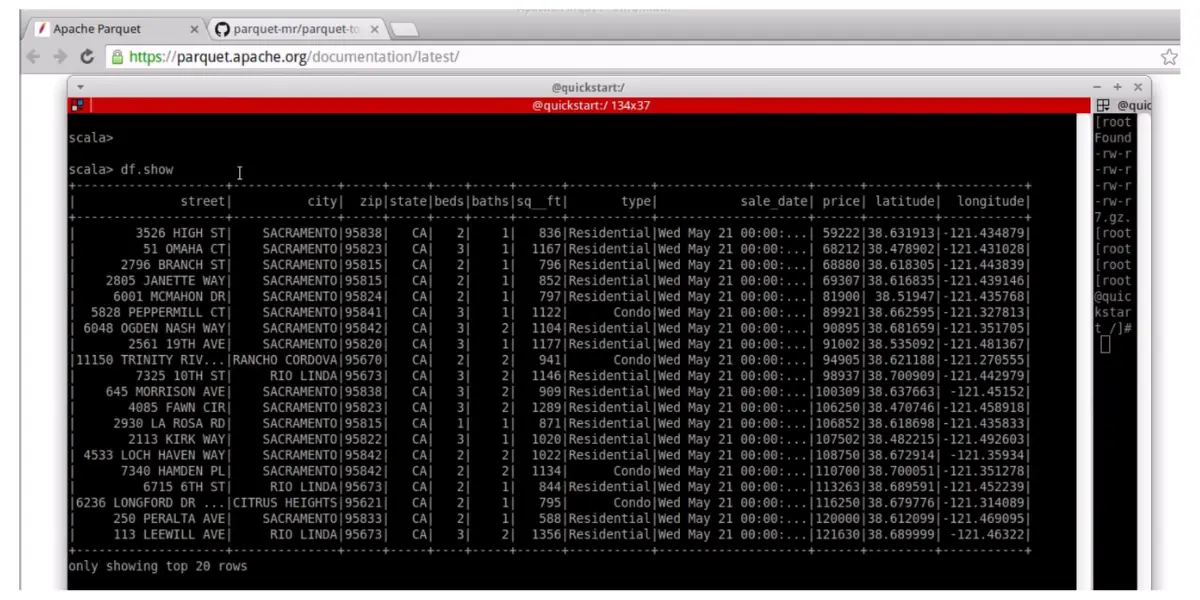
Theory of Apache Parquet
Block ( HDFS- Hadoop file distributed system)
Parquet is an incredibly efficient file format specially designed to be optimally used with HDFS. It compresses large volumes of data into neat blocks that are easy to work with and access.
File
An HDFS file has been created containing the vital metadata necessary to accurately track and reference its contents without needing any of the actual data included.
Row Group
A logical arrangement that provides a systemized way of organizing data into distinct rows. With this structure, each column in the dataset is allocated its section within every row group to ensure every essential information gets noticed amongst the records.
Column chunk
Your data is carefully organized and stored in meticulously arranged row groups, assuring that each column will be easily accessible.
Page
Columns are divided into distinct sections called these as the building blocks that enable data to be efficiently compressed and encoded. In addition, each page type can be strategically sequenced within each column chunk, unlocking many possibilities.
File Formats
Configuration
- Row group size: By grouping database rows and distributing them among larger columns, powerful sequential IO is possible. However, since each group can require more buffering during the writing process to execute effectively, this may necessitate a two-pass approach for maximum efficiency.
- Data page size: Regarding data pages, size matters; opting for smaller ones provides greater pre terms of looking up single rows. On the other hand, using larger page sizes can keep space requirements low and reduce time spent on parsing headers.
Extensibility
Through a modular system, developers can easily extend the format by adding new features, such as versions for files and encodings specified through enums and page types, which won’t cause confusion when skipped.
- File version
- Encoding
- Page types
Metadata
Three types of metadata are serialized using the TcompactProtocol.
- File metadata
- Column( chunk )metadata
- Page header metadata
Different Types of Parquet
The file format emphasizes efficient disk storage, striving to use as few data types as possible. Below are the two types.
Logical Type
It has simplified the way data is interpreted while preserving efficient storage methods by introducing logical types. This ensures that the set of primitive types remains minimal and allows for greater flexibility in how each class can be used.
Nested Encoding
Parquet employs Dremel encoding to structure nested columns and optimizes storage space, maximizing efficiency.
By examining the schema of a column, it can compute both definition and repetition levels. All these factors together determine precisely how much memory can be saved.
Apache Parquet User Examples
- Hadoop
- Apache Iceberg/stream processing
- Delta lake
- Apache spark
Advantages
- Efficient for storing big and different kinds of data
- Reliable and secure data storage
- Flexible compression option and
- Its columnar storage is better than row-based files like CSV
- It works with AWS Athena, Amazon Redshift spectrum, Google big query, etc.
- Increased data throughput and performance
Disadvantages
- Difficult to change schema over time
- Mutability is hard
- Need more memory to stuff columnar format
- Gathering the data is a tuff task
FAQs
What is the maximum size of the Parquet file?
These software files remain remarkably constant in size despite the number of rows, ranging from 50 million to 251 million at about 210MB each. Only as row numbers increase does file size start to grow.
Which compression is best for Parquet?
LZ4 is the fastest algorithm, while GZIP, with its impressive compression rate, lags. Snappy and Parquet boast equal rates of compression, but Snappy edges ahead in speed, nearly matching LZ4 on this front.
Which encoding does Parquet use?
It compresses column values using RLE encoding for improved storage efficiency. In addition, TheRunLengthBitPackingHybridEncoder and ValuesWriter ensure data pages contain only Dictionary indices, Boolean values, repetition levels, and definition levels to save space without sacrificing any crucial information.
Conclusion
Apache Parquet is a powerful and reliable columnar data storage format that makes it easy to query large datasets quickly and efficiently.
With its open-source license, scalability, enhanced security, and performance, Apache Parquet is an ideal solution for organizations looking to store and analyze more flexibility than traditional row-based databases.
Reference