
Data architecture for machine learning is a critical element of success for implementing any artificial intelligence or machine learning project.
Data architecture defines how data will be collected, processed, and stored to enable the training and execution of AI/ML models.
This article will explore the different types and components of ML architectures, the important factors and considerations when designing data architecture for ML, data flow in machine learning, and tips for choosing the right data architecture.
Before moving to data architecture for machine learning, let us know about data architecture.
What is data architecture?
The term “data architecture” typically refers to how data is organized and accessed within a system.
That can include the layout of data stores, the use of middleware and APIs, and the design of data models. A well-architected system will make it easy to access and analyze data, which is essential for machine learning.
What is data architecture in machine learning?
Data architecture in machine learning is the design of a system that stores and accesses data to enable machine learning algorithms to function.
It includes the design of the data structures used and the algorithms and techniques for managing and accessing the data.
Types of machine learning architectures
There are three main types of machine learning architecture.
- Supervised learning – Uses a training dataset to teach a machine how to perform a task.
- Unsupervised learning – It doesn’t use a training dataset; instead, it tries to find patterns in the data itself.
- Reinforcement learning – Relies on feedback from an environment to teach a machine how to perform a task.
Components of machine learning architecture

The components of machine learning architecture typically include a data pre-processing step, a feature extraction step, a model training step, and a model evaluation step.
Data pre-processing step
This step typically includes data cleaning, normalization, and feature selection tasks. That means removing duplicate or irrelevant data and transforming it into a consistent format so that the machine learning algorithm can easily process it.
Feature extraction step
This step involves extracting features from the data the machine learning algorithm will use.
Feature extraction is identifying and extracting the features of interest from the data. It can be a manual process, or it can be automated using machine learning algorithms. The goal is to identify the most important features for predicting the desired outcome.
Model training step
The machine learning algorithm is trained on the data using the extracted features in this step.
Model training teaches a computer how to perform tasks like recognizing objects in images or translating text. This process begins by feeding the computer a large set of training data, which it uses to learn the underlying patterns.
Once the computer has learned these patterns, it can then apply them to new data to perform the desired task.
Model evaluation step
This step evaluates the machine learning algorithm’s performance on unseen data.
Model evaluation is important to ensure the accuracy of a machine-learning model. There are a variety of techniques that can be used, such as cross-validation and bootstrapping.
These help determine how well the model performs and identify any potential problems. To evaluate the performance of a machine learning model, one must first select a dataset to use for testing and then measure the accuracy of the model on that dataset.
The most common standard of accuracy is called “error rate,” which is simply the percentage of incorrect predictions made by the model. Other standards of accuracy include precision and recall.
Factors
Factors that need to be considered while designing data architecture for machine learning are
The type of ML algorithm(s)
The data architecture for machine learning will vary depending on the ML algorithm(s) being used.
For example, large data sets with lots of training data are required if a deep neural network is used. On the other hand, smaller data sets can be used if we use a decision tree.
The data set(s) being used for training and inference
The data set(s) used for training and data collection are also important factors when designing data architecture.
For example, data sets with lots of data points will require more storage space, while smaller data sets may not need as much storage capacity.
Input data accuracy
The accuracy of the data is also a factor since poor-quality input data can negatively impact ML models.
The compute infrastructure
When designing data architecture for machine learning, it is important to consider the computing infrastructure used.
The computing infrastructure will determine the type of ML algorithm(s) used and the dimension of data sets that can be processed.
For example, large data sets can be processed without issue if a data center is being used. However, if a cloud data center is being used, then data sets may be limited by the amount of data transferred over the network or even stored in the cloud.
Hybrid or single-source approach
The data architecture for machine learning will also depend on whether you use a hybrid or single-source approach to train your ML models. A hybrid approach uses multiple data sources to train an ML model and make data-driven decisions.
Single-source approaches use data from one data source to train an ML model and make data-driven decisions. Hybrid data architectures are more scalable than single data source approaches and can be used to train large data sets with lots of data points efficiently.
Apart from this, factors like Storage requirements (processing, memory, disk),
Network bandwidth and latency and The data pipeline for data collection, storage, processing, and training are also to be considered.
Data flow in machine learning
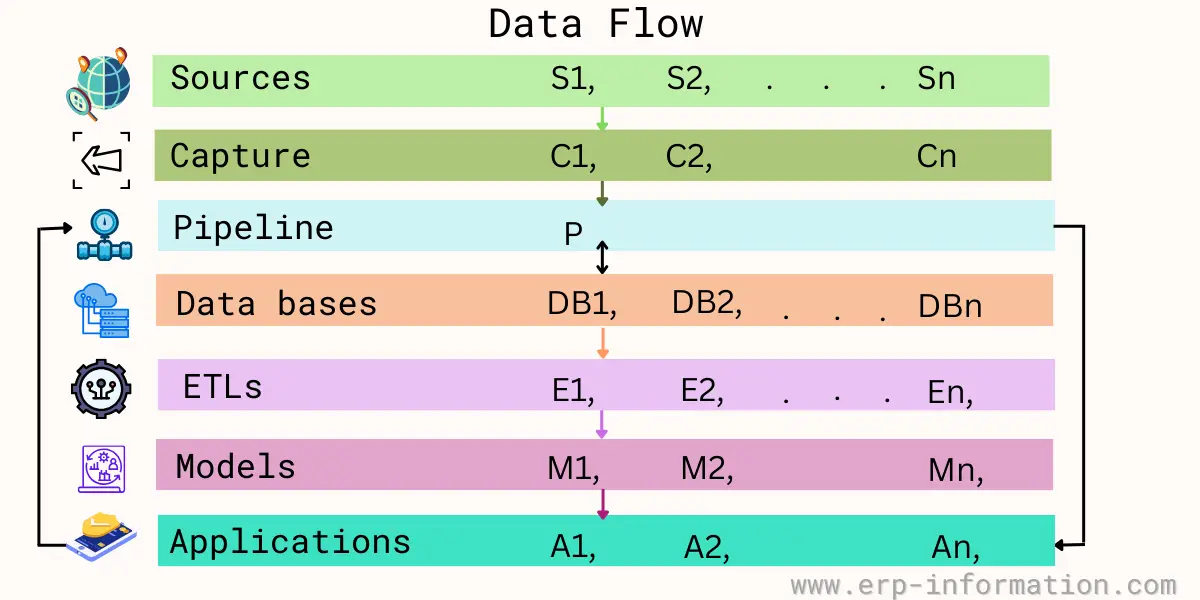
Data goes through all their layers.
Sources
Sources consist of
- Internal files and internal data basis
- Public data
- Smartphone apps
- Websites
- Social media
- Data stream
- IoT devices
- Corporate internal process
Capture
Capture consists of
- IoT interface
- Website scraping
- The internal corporate process feeds
- Website and smartphone chat dialogues
Pipeline
Pipeline consists of
- Data integration
- Data temporary storage
- Data subscription
- Data publication
Databases
Databases consist of
- Data lake
- Graph database
- Document database
- Sequel database
ETLs
ETLs consists of
- Extraction – Getting data from selected sources
- Transformation – Normalization, regulation, aggregation
- Load functioning – Data saving in standard format for use in modeling processes
Models
Models consist of
- Regression analysis
- Decision tree
- Cluster analysis
- Probabilistic graphical models
- Artificial neural networks
Applications
Applications consist of
- Image recognition
- Face recognition
- Medical diagnosis
- Malware detection
- Autonomous vehicles
Tips for choosing the right data architecture for machine learning
- Choose the right data architecture for your needs. Make sure to consider the amount of data you have, the type of data, and the complexity of your algorithms.
- Use a big data platform if you have a large amount of data. That will ensure that your data can be processed quickly and efficiently.
- Use a streaming data platform if you need to process data in real time. It will allow you to keep up with fast-moving data streams.
- Use a graph database if your data is complex or has a lot of relationships between different entities. That makes it easier to navigate and process your data.
- Consider using a hybrid approach if your data doesn’t fit into one category. That will allow you to get the benefits of multiple different architectures.
FAQs
Why is data architecture vital for machine learning projects?
Data architecture plays a critical role in ML projects as it ensures the collection, storage, and availability of relevant data for model training. A well-designed data architecture streamlines the entire ML workflow.
How does data architecture impact the performance of machine learning models?
The quality of data and the efficiency of data pipelines directly influence the accuracy and reliability of ML models. Poor data architecture can lead to biased or inaccurate results.
What is the relationship between data architecture and data governance in machine learning?
Data governance ensures that data is managed, used, and protected appropriately. It works hand in hand with data architecture to maintain data quality, security, and compliance.
Conclusion
Machine learning is a complex process that relies on accurate data. Therefore, the data architecture you choose for your machine learning project will significantly impact the accuracy and speed of your results.
This article outlined the types and components of machine learning architecture and five tips to help you choose the right data architecture for your needs. We hope these tips help you start your machine learning project and achieve better results faster.
Reference